第12章:异常处理与恢复
通过强大的错误检测和恢复机制构建弹性AI智能体
第12章:异常处理与恢复
为了使AI智能体在多样化的现实世界环境中可靠运行,它们必须能够管理意外情况、错误和故障。就像人类适应意外障碍一样,智能智能体需要强大的系统来检测问题、启动恢复程序,或至少确保受控失败。这一基本需求构成了异常处理与恢复模式的基础。
这种模式专注于开发异常耐用和弹性的智能体,能够在各种困难和异常情况下保持不间断的功能和操作完整性。它强调主动准备和反应策略的重要性,以确保即使在面临挑战时也能持续运行。这种适应性对于智能体在复杂和不可预测的环境中成功运行至关重要,最终提高其整体有效性和可信度。
处理意外事件的能力确保这些AI系统不仅智能,而且稳定可靠,这促进了对其部署和性能的更大信心。集成全面的监控和诊断工具进一步增强了智能体快速识别和解决问题的能力,防止潜在的中断并确保在不断变化的条件下的更平稳运行。这些高级系统对于维护AI操作的完整性和效率至关重要,增强了其管理复杂性和不可预测性的能力。
这种模式有时可能与反思一起使用。例如,如果初始尝试失败并引发异常,反思过程可以分析失败并使用改进的方法(如改进的提示)重新尝试任务以解决错误。
异常处理与恢复模式概述
异常处理与恢复模式解决了AI智能体管理操作失败的需求。这种模式涉及预测潜在问题,如工具错误或服务不可用,并制定缓解策略。这些策略可能包括错误日志记录、重试、回退、优雅降级和通知。此外,该模式强调恢复机制,如状态回滚、诊断、自我纠正和升级,以将智能体恢复到稳定操作。实现这种强大的异常处理和恢复模式可以将AI智能体从脆弱和不可靠的系统转变为能够在具有挑战性和高度不可预测的环境中有效和弹性运行的强大、可靠的组件。这确保智能体保持功能、最小化停机时间,即使在面临意外问题时也能提供无缝和可靠的体验。
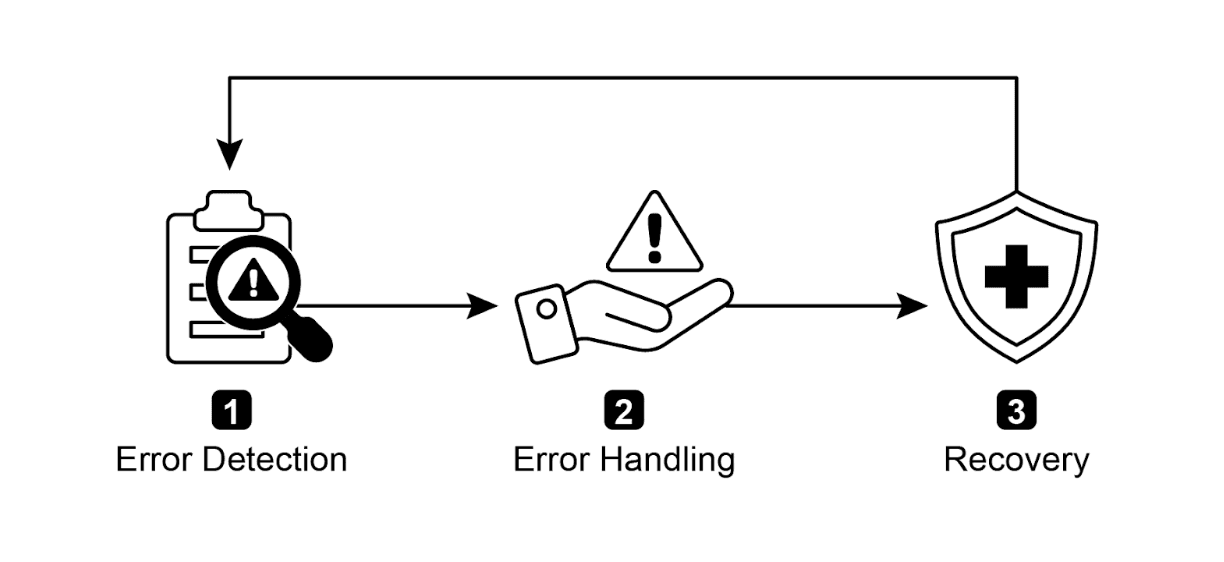
图1:AI智能体异常处理和恢复的关键组件
错误检测: 这涉及在操作问题出现时仔细识别它们。这可能表现为无效或格式错误的工具输出、特定API错误(如404(未找到)或500(内部服务器错误)代码)、来自服务或API的异常长响应时间,或偏离预期格式的不连贯和无意义的响应。此外,可能实施其他智能体或专门监控系统的监控,以进行更主动的异常检测,使系统能够在问题升级之前捕获潜在问题。
错误处理: 一旦检测到错误,精心设计的响应计划至关重要。这包括在日志中仔细记录错误详情以供后续调试和分析(日志记录)。重试行动或请求,有时使用略微调整的参数,可能是一个可行的策略,特别是对于瞬态错误(重试)。利用替代策略或方法(回退)可以确保维护某些功能。在无法立即完全恢复的情况下,智能体可以维护部分功能以提供至少一些价值(优雅降级)。最后,在需要人工干预或协作的情况下,向人工操作员或其他智能体发出警报可能至关重要(通知)。
恢复: 这个阶段是关于在错误后将智能体或系统恢复到稳定和操作状态。它可能涉及逆转最近的更改或事务以撤销错误的影响(状态回滚)。对错误原因进行彻底调查对于防止再次发生至关重要。通过自我纠正机制或重新规划过程调整智能体的计划、逻辑或参数可能需要避免将来出现同样的错误。在复杂或严重的情况下,将问题委托给人工操作员或更高级别的系统(升级)可能是最佳行动方案。
实现这种强大的异常处理和恢复模式可以将AI智能体从脆弱和不可靠的系统转变为能够在具有挑战性和高度不可预测的环境中有效和弹性运行的强大、可靠的组件。这确保智能体保持功能、最小化停机时间,即使在面临意外问题时也能提供无缝和可靠的体验。
实践代码示例
异常处理实现
import logging
import time
from typing import Any, Callable, Optional
from functools import wraps
class ExceptionHandler:
"""异常处理器"""
def __init__(self, max_retries: int = 3, retry_delay: float = 1.0):
self.max_retries = max_retries
self.retry_delay = retry_delay
self.logger = logging.getLogger(__name__)
def retry_on_exception(self, exceptions: tuple = (Exception,)):
"""重试装饰器"""
def decorator(func: Callable) -> Callable:
@wraps(func)
def wrapper(*args, **kwargs) -> Any:
last_exception = None
for attempt in range(self.max_retries + 1):
try:
return func(*args, **kwargs)
except exceptions as e:
last_exception = e
if attempt < self.max_retries:
self.logger.warning(
f"尝试 {attempt + 1} 失败: {e}. "
f"在 {self.retry_delay} 秒后重试..."
)
time.sleep(self.retry_delay)
else:
self.logger.error(f"所有重试失败: {e}")
raise last_exception
return wrapper
return decorator
def handle_exception(self, func: Callable, *args, **kwargs) -> Any:
"""处理异常"""
try:
return func(*args, **kwargs)
except Exception as e:
self.logger.error(f"函数 {func.__name__} 执行失败: {e}")
return self._fallback_response(e)
def _fallback_response(self, exception: Exception) -> Any:
"""回退响应"""
return {
"error": True,
"message": "操作失败,使用回退响应",
"exception": str(exception)
}
# 使用示例
def demonstrate_exception_handling():
"""演示异常处理"""
handler = ExceptionHandler(max_retries=3, retry_delay=1.0)
@handler.retry_on_exception((ValueError, ConnectionError))
def risky_operation(value: int) -> int:
"""可能失败的操作"""
if value < 0:
raise ValueError("值不能为负数")
if value > 100:
raise ConnectionError("连接超时")
return value * 2
# 测试重试机制
try:
result = risky_operation(150)
print(f"操作成功: {result}")
except Exception as e:
print(f"操作最终失败: {e}")
# 测试回退机制
result = handler.handle_exception(risky_operation, -5)
print(f"回退响应: {result}")
if __name__ == "__main__":
demonstrate_exception_handling()恢复机制实现
import json
from datetime import datetime
from typing import Dict, Any, List
class RecoveryManager:
"""恢复管理器"""
def __init__(self):
self.checkpoints = []
self.recovery_strategies = {}
def create_checkpoint(self, state: Dict[str, Any], checkpoint_id: str = None):
"""创建检查点"""
if checkpoint_id is None:
checkpoint_id = f"checkpoint_{len(self.checkpoints)}"
checkpoint = {
"id": checkpoint_id,
"timestamp": datetime.now(),
"state": state.copy(),
"status": "active"
}
self.checkpoints.append(checkpoint)
return checkpoint_id
def rollback_to_checkpoint(self, checkpoint_id: str) -> bool:
"""回滚到检查点"""
for checkpoint in reversed(self.checkpoints):
if checkpoint["id"] == checkpoint_id:
# 恢复状态
self._restore_state(checkpoint["state"])
checkpoint["status"] = "restored"
return True
return False
def _restore_state(self, state: Dict[str, Any]):
"""恢复状态"""
# 实现状态恢复逻辑
print(f"恢复状态: {state}")
def register_recovery_strategy(self, error_type: str, strategy: Callable):
"""注册恢复策略"""
self.recovery_strategies[error_type] = strategy
def execute_recovery(self, error_type: str, error_context: Dict[str, Any]) -> bool:
"""执行恢复"""
if error_type in self.recovery_strategies:
try:
strategy = self.recovery_strategies[error_type]
result = strategy(error_context)
return result
except Exception as e:
print(f"恢复策略执行失败: {e}")
return False
return False
def get_checkpoint_history(self) -> List[Dict[str, Any]]:
"""获取检查点历史"""
return self.checkpoints.copy()
# 使用示例
def demonstrate_recovery():
"""演示恢复机制"""
recovery = RecoveryManager()
# 创建检查点
state1 = {"step": 1, "data": "initial"}
checkpoint1 = recovery.create_checkpoint(state1, "init")
state2 = {"step": 2, "data": "processed"}
checkpoint2 = recovery.create_checkpoint(state2, "processed")
# 注册恢复策略
def retry_strategy(context):
print(f"执行重试策略: {context}")
return True
def fallback_strategy(context):
print(f"执行回退策略: {context}")
return True
recovery.register_recovery_strategy("retry", retry_strategy)
recovery.register_recovery_strategy("fallback", fallback_strategy)
# 执行恢复
recovery.execute_recovery("retry", {"attempt": 1})
recovery.execute_recovery("fallback", {"reason": "timeout"})
# 回滚到检查点
success = recovery.rollback_to_checkpoint("init")
print(f"回滚成功: {success}")
if __name__ == "__main__":
demonstrate_recovery()监控和诊断实现
import psutil
import threading
import time
from typing import Dict, Any, List
class SystemMonitor:
"""系统监控器"""
def __init__(self):
self.metrics = {}
self.alerts = []
self.monitoring = False
self.monitor_thread = None
def start_monitoring(self, interval: float = 1.0):
"""开始监控"""
self.monitoring = True
self.monitor_thread = threading.Thread(
target=self._monitor_loop,
args=(interval,)
)
self.monitor_thread.start()
def stop_monitoring(self):
"""停止监控"""
self.monitoring = False
if self.monitor_thread:
self.monitor_thread.join()
def _monitor_loop(self, interval: float):
"""监控循环"""
while self.monitoring:
self._collect_metrics()
self._check_thresholds()
time.sleep(interval)
def _collect_metrics(self):
"""收集指标"""
self.metrics = {
"cpu_percent": psutil.cpu_percent(),
"memory_percent": psutil.virtual_memory().percent,
"disk_percent": psutil.disk_usage('/').percent,
"timestamp": time.time()
}
def _check_thresholds(self):
"""检查阈值"""
if self.metrics["cpu_percent"] > 80:
self._create_alert("CPU使用率过高", "warning")
if self.metrics["memory_percent"] > 90:
self._create_alert("内存使用率过高", "critical")
if self.metrics["disk_percent"] > 95:
self._create_alert("磁盘空间不足", "critical")
def _create_alert(self, message: str, level: str):
"""创建警报"""
alert = {
"timestamp": time.time(),
"message": message,
"level": level,
"resolved": False
}
self.alerts.append(alert)
print(f"警报 [{level.upper()}]: {message}")
def get_metrics(self) -> Dict[str, Any]:
"""获取指标"""
return self.metrics.copy()
def get_alerts(self, level: str = None) -> List[Dict[str, Any]]:
"""获取警报"""
if level:
return [alert for alert in self.alerts if alert["level"] == level]
return self.alerts.copy()
def resolve_alert(self, alert_index: int):
"""解决警报"""
if 0 <= alert_index < len(self.alerts):
self.alerts[alert_index]["resolved"] = True
# 使用示例
def demonstrate_monitoring():
"""演示监控系统"""
monitor = SystemMonitor()
# 开始监控
monitor.start_monitoring(interval=2.0)
try:
# 运行一段时间
time.sleep(10)
# 获取指标
metrics = monitor.get_metrics()
print(f"系统指标: {metrics}")
# 获取警报
alerts = monitor.get_alerts()
print(f"警报数量: {len(alerts)}")
finally:
# 停止监控
monitor.stop_monitoring()
if __name__ == "__main__":
demonstrate_monitoring()一览
什么: 智能体在现实世界中运行时会遇到各种错误和异常情况。没有强大的异常处理机制,智能体可能因单个错误而完全失败。
为什么: 异常处理与恢复模式通过以下方式提供解决方案:
- 检测和识别错误和异常
- 提供重试和回退机制
- 实现状态恢复和回滚
- 支持优雅降级
- 提供监控和诊断能力
经验法则: 当智能体需要在不可预测环境中运行、处理外部依赖或需要高可靠性时使用异常处理与恢复模式。它特别适用于:
- 关键任务系统
- 外部API集成
- 数据处理管道
- 实时系统
- 容错系统
关键要点
- 异常处理包括错误检测、处理和恢复三个阶段
- 重试机制可以处理瞬态错误
- 回退策略确保部分功能可用
- 检查点和回滚支持状态恢复
- 监控和诊断提供主动错误检测
- 现代框架提供内置的异常处理支持
结论
异常处理与恢复模式是构建弹性、可靠智能体系统的关键组件。通过提供强大的错误检测、处理和恢复机制,这种模式使智能体能够在不可预测的环境中有效运行。
掌握异常处理与恢复模式对于构建能够在现实世界复杂环境中可靠运行的智能体系统至关重要。它提供了处理错误、恢复状态和维持服务可用性所需的工具和技术,使智能体能够提供稳定和可靠的服务。